
这篇文章收录于BMVC2020,主要的思想是减少anchor-free目标检测中的label噪声,在COCO小目标检测上表现SOTA!性能优于FreeAnchor、CenterNet和FCOS等网络。整体思路可以说相当简单,就是在原来的基础上增加了标签池化和目标框聚合操作,其实可以看作是tricks。
论文地址:https://arxiv.org/pdf/2008.01167.pdf
代码地址(基于mmdetection实现):https://github.com/nerminsamet/ppdet
当前的anchor-free目标检测器将空间上落在ground truth标签边界框box的预定中心区域内的所有特征标记为正。这种方法会在训练过程中引起标签噪音Label Noise,因为其中一些带有正标签的特征可能位于背景或遮挡物上,或者根本不是有判别性的特征。在本文中,提出了一种新的标记策略,旨在减少anchor-free目标检测器中的标记噪声。具体将源于各个特征的预测汇总为一个预测,这使模型可以减少训练过程中非判别性特征(non-discriminatory features)的贡献。在此基础上,开发了一种新的单阶段anchor-free目标检测器PPDet,以在训练过程中采用这种标记策略,并在推理过程中采用类似的预测合并方法。在COCO数据集上,PPDet在anchor-free的自上而下检测器中实现了最佳性能,并与其他最新方法具有同等水平。它在检测小物体方面也优于所有最新方法(AP 31.4)。
简介
早期的基于深度学习的目标检测器算法是两阶段的,在第一阶段,生成了一组稀疏的目标候选框,并在第二阶段将它们进行了卷积神经网络(CNN)的分类。后来,在单阶段目标检测的想法越来越引起人们的关注,在单阶段方法中,设置预定义的anchor替换了候选框。一方面,anchor锚点必须密集地覆盖图像(例如位置,形状和比例等方面)以使召回率最大化。另一方面,应该将它们的数量保持在最小,以减少推理时间和在训练中造成的不平衡问题。
目前主要有两类突出的方法来进行anchor-free的目标检测。第一类是基于关键点的、自下而上的方法,在开创性工作CornerNet之后流行起来。这类方法首先检测物体的关键点(如角点、中心点和极点),然后对它们进行分组得到整体物体的检测。第二类方法遵循自上而下的方法,直接预测每个物体上的类和边界框坐标并确定其在最终特征图中的位置。
目标检测器训练的一个重要方面是用于标记目标候选者的策略,这些候选者可以是提案、锚或最终特征图中的位置(即特征)。 为了在训练过程中给候选目标贴上 "正样本"(前景foreground)或 "负样本"(背景background)的标签,已经提出了多种策略,例如有基于交并比(IoU)的方法、基于关键点和与ground truth box的相关位置的方法等。
具体来说,在自上而下的anchor-free目标检测器中,当输入图像通过骨干网络中的特征提取器和FPN后,空间上落在ground truth框内的特征被标记为正值,而其他特征被标记为负值,当然在这两者中间还有一个 "忽略ignore "区域。其中,每一个正标签的特征都作为一个独立的预测对损失函数做出贡献。然而,这种方法的问题是,有些正样本标签中的可能是错误的或标记的质量较差,因此,它们在训练过程中注入了标签噪声。噪声标签主要来自:(i)物体上的非判别性特征,(ii)框内的背景特征,(iii)遮挡物(图1)。 在本文中提出了一种anchor-free目标检测方法,该方法放宽了正样本标签策略,使模型能够减少训练时非判别性特征的贡献。同时,根据这种训练策略,检测器采用了一种推理方法,使得其中高度重叠的预测相互强制。

图1:PPDet的三个样本检测,从左到右分别是冲浪板,笔记本电脑和球拍。彩色圆点显示了将其预测汇总在一起以生成最终检测结果的位置,显示在绿色边框中。颜色表示贡献权重。最高贡献来自目标对象,而不是遮挡物或背景区域。
本文的方法在训练过程中,在ground truth(GT)框内定义了一个“正区域”,该区域与GT框具有相同的形状和中心,并且作者通过实验调整了相对于GT框的正区域的大小。由于这是一种anchor-free方法,因此每个特征(即最终特征图中的位置)都可以预测类别概率矢量和边界框坐标。来自GT框正区域的分类预测汇总在一起,并作为单个预测对损失做出了贡献。由于在训练过程中来自非目标区域(背景或被遮挡区域)的特征和非判别行特征的贡献会自动降低,因此这种总和缓解了上面提到的“噪声标签”问题。模型推理时,高度重叠的框的类别概率再次被合并在一起以获得最终的类别概率。方法最终命名为“ PPDet”,它是“prediction pooling detector”的缩写。
本文工作的贡献有两个方面:(i)设计了一个宽松的标签策略,它允许模型在训练过程中减少非判别性特征的贡献,(ii)提出一个新的目标检测方法:PPDet,它使用这个宽松的策略进行训练,并使用了一个新的基于预测池(prediction pooling)的推理方法。在COCO数据集上,PPDet优于所有自上而下的anchor-free检测器,并且与其他最先进的方法表现相当。特别的,PPDet对于检测小物体尤其有效。
本文方法
1、Labeling strategy and training
Anchor-free检测器通过根据GT框的尺度大小或目标回归距离将其分配到适当的FPN层级来限制GT框的预测。在本文中同样遵循基于尺度的分配策略,因为它是一种自然地将GT框与特征金字塔层级特性关联起来的方法。然后,为每个GT框构建两个不同的区域,将 "正区域 "定义为与GT框同中心且形状与GT框相同的区域,并通过实验设定 "正区域 "的大小。然后,将在空间上落在GT盒的 "正区域 "内的所有位置(即特征)识别为 "正(前景)"特征,其余为 "负(背景)"特征,这样,每个正向特征都被分配到包含它的GT框中。
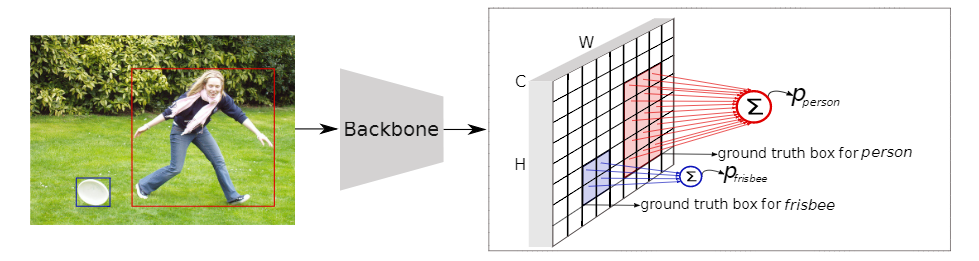
图2:PPDet训练期间的预测池predict pool。为简单起见,仅以单FPN层级进行说明,并且未显示边界框回归分支。蓝色和红色单元格是前景单元格。将相同颜色的前景单元(每个都是c维矢量)进行合并(即求和),以形成对应对象的最终预测得分。这些合并的得分被送到损失函数(Focal loss)中进行训练
在图2中,蓝色和红色的单元格代表正向特征,其余的(空的或白色的)是负向特征。蓝色特征被分配给飞盘(frisbee),红色特征被分配给人物(person)。为了得到一个目标实例的最终检测分数,本文将所有分配给该目标对象的特征的分类分数集中起来,将它们加在一起,得到一个最终的C维向量,C表示目标的类别数。除了正向标记的特征外,其他特征都是负值特征,而每个负值特征对损失都有单独的贡献(即没有汇集),这个最终的预测向量被送入Focal Loss(FL)。
默认情况下,将正特征分配给它们所在的框的目标实例,而此时,在不同GT框的相交区域中的特征分配是需要处理的问题。在这种情况下,本文的方法会将这些特征分配到距其中心距离最小的GT框中。与其他anchor-free方法相似,在本文的模型中,会对分配给目标对象的每个前景特征进行训练以预测其目标的GT框的坐标。
2、 Inference推理
PPDet的推理流程如图3所示。首先,将输入图像送入到产生初始检测集的主干神经网络模型。每次检测都与(i)边界框、(ii)目标类别(选择为具有最大概率的类)和(iii)置信度得分相关联。在这些检测中,将消除使用背景类标记的检测,并将在此阶段剩余的每个检测都视为对其所属目标类别的投票,其中方框是目标位置的假设,置信度得分是投票的强度。如果属于同一目标类别的两个检测重叠超过一定量(即交并比(IoU)> 0.6),则将它们视为对同一目标的投票,并且每个检测的得分相比于其他检测的分数增加k的(IoU-1.0)次方倍,其中K为常数。因此,IoU越多,增加幅度越大。将这一过程应用于每对检测后,将获得最终检测的分数。此步骤之后是NMS操作,该操作会产生最终检测结果。
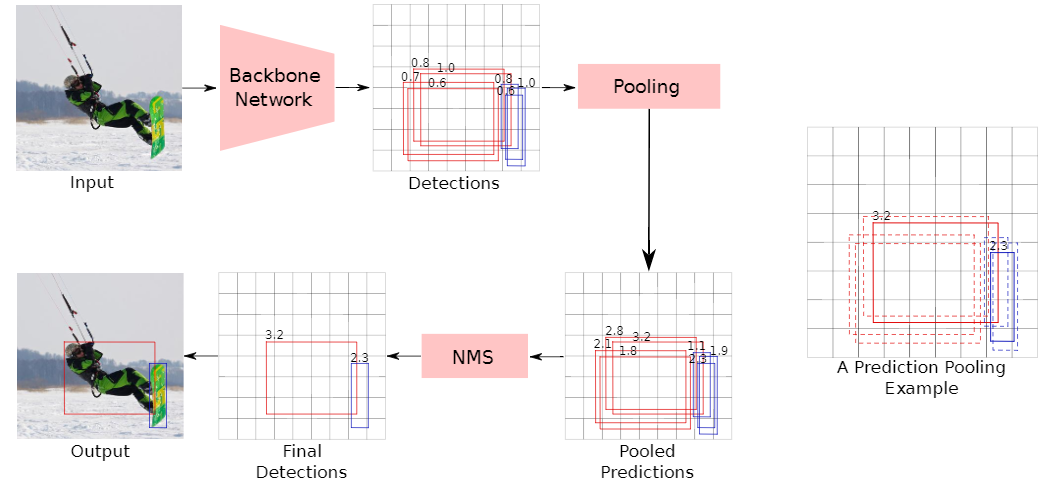
图3 :(左)PPDet推理流程的示意图。预测的人和滑雪板框分别以红色和蓝色显示。红色和蓝色方框相互投票。(右)一个pooling示例。虚线边界红框投给实线红框,虚线边界蓝框投给实线蓝框。图中显示的是实心框的最终得分(汇总后)。
值得注意的是,尽管推理中使用的预测池似乎与训练中使用的池不同,但实际上,它们是相同的过程。训练中使用的假设是由正区域中的特征预测的边界框彼此完全重叠(即IoU = 1),可以看作推理过程的一个特例。
3、 网络框架
PPDet使用RetinaNet的网络模型作为整体框架,它由一个主干卷积神经网络(CNN)和一个特征金字塔网络(FPN)组成。FPN计算多尺度的特征表示,并产生五个不同尺度的特征图。在每个FPN层的顶部有两个独立的并行网络,即分类网络和回归网络。分类网络输出一个W×H×C的张量,其中W和H是空间维度(分别是宽度和高度),C是类别数量。同样,回归网络输出一个W×H×4的张量,其中4是边界框坐标的数量,并将这些张量中的每个像素称为一个特征。
数据集: COCO
消融实验:
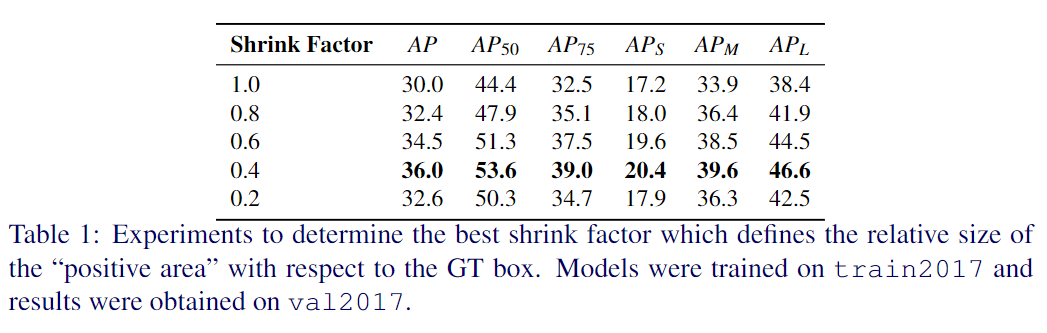
1、Size of the “positive area”
如前所述,将“正区域”定义为与GT框同心且形状与GT框相同的区域。实验中通过将“正区域”的宽度和高度乘以收缩因子来调整其大小。用收缩系数在1.0和0.2之间进行了实验。表1中显示了性能结果。但是,从缩小系数1.0到0.4,mAP会增加,但是在那之后性能会急剧下降。基于这种消融,将其余的实验的收缩因子设置为0.4。
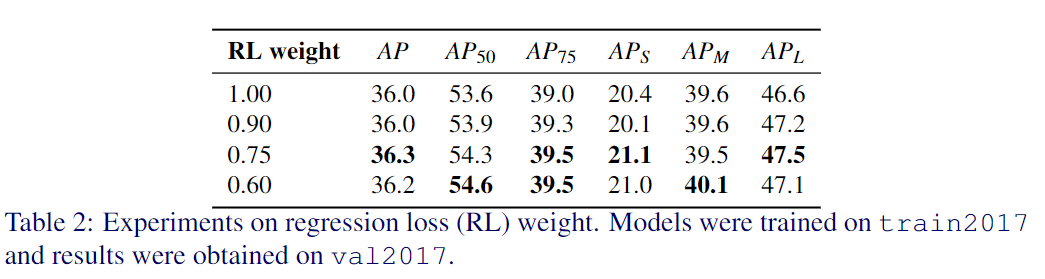
2、Regression loss weight
为了找到分类和回归损失之间的最佳平衡,对回归损失权重进行了消融实验。如表2所示,最好的结果是0.75。在其余的实验中,也将回归损失的权重设置为0.75。
对比实验
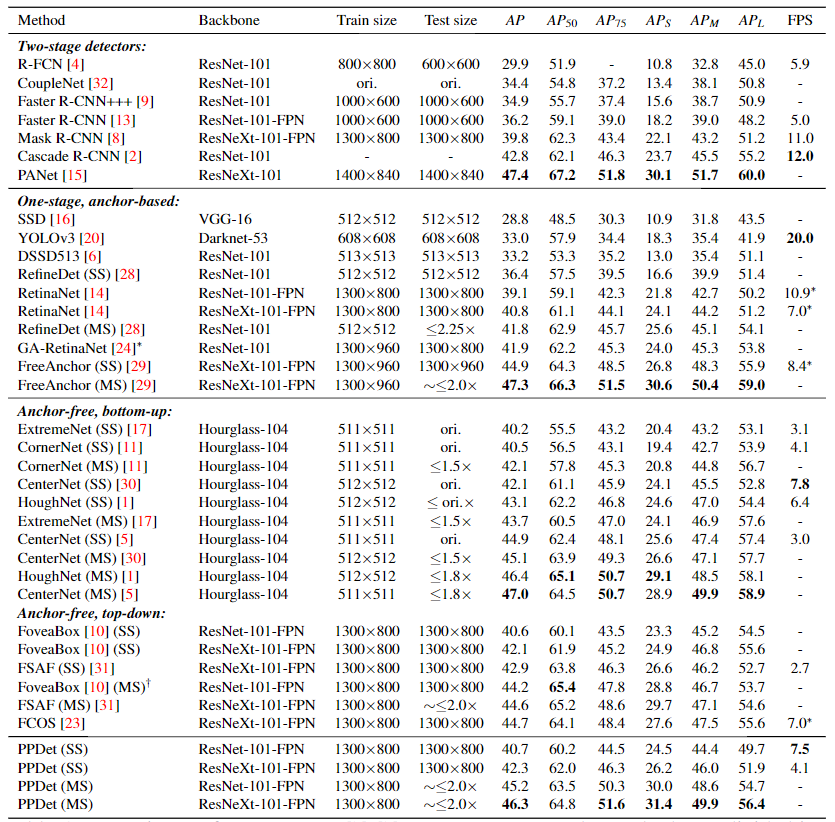
更多细节可参考论文原文。
(以上文章转载自AI算法修炼营 ,原文链接:https://mp.weixin.qq.com/s/s5UumLohBUvOmzRPv8FGWw,如涉及版权,请与网站编辑联系zwli@semi.ac.cn)